
序論
このセクションでは、様々なタイプのネットワークレイアウトで冗長系監視ホストを実現するためのいくつかのシナリオについて述べます。 冗長系ホストを使って、Nagiosを実行する主要なホストが停止したり、あなたのネットワークの一部にアクセスできなくなる場合に、あなたのネットワークを監視を維持することができます。
注意: もし、Nagiosの使用方法を学んでいるところであれば私が示した 前提条件になれるまでは、冗長化を試さないように提案します。 冗長系は、理解するのに比較的複雑な問題であり、適切に実行させるのも難しいのです。
前提条件
冗長系の実行について考える前に、以下をよく知っている必要があります?…
- ホストとサービスのためにイベントハンドラの実装
- シェルスクリプト経由で外部コマンドをNagiosに発行します。
- NRPEアドオンまたは、他の方法を利用して リモートホスト・プラグインを実行します。
- check_nagios プラグインにNagiosプロセスの状態について問い合わせます。
サンプル・スクリプト: このドキュメントの中で使用するサンプル・スクリプトは、Nagiosディストリビューションのサブディレクトリ内のeventhandlers/ですべて見つけることができます。 ただ、システム上で実行させるには、修正が必要でしょう・・・。
シナリオ1-- 監視の冗長系
序論
この方法は、あなたのネットワーク上で冗長監視ホストを実現する簡単(かつ素朴な)方法です。また、それは限られた数の失敗から守ってくれるでしょう。 異なるネットワークセグメントなどを超えて、より賢い冗長系、より良い冗長系を提供するためには、よる複雑なセットアップが必要です。
目標
この種の冗長系の目的は単純です。 「マスター」と「スレーブ」の両方のホストはネットワークで同じホストとサービスを監視します。 普通の状況の下では、「マスター」ホストだけが問題に関する通知先に"通知"を送るでしょう。私たちは「スレーブ」ホストが、次のような問題に対して連絡先に通知する仕事を引き継いでNagiosを実行することを望みます:
- Nagiosを実行している「マスター」ホストが停止してたかまたは、・・・
- 「マスター」ホストの上のNagiosプロセスは、何らかの理由でストップしている。
ネットワーク構成図
以下の図は非常に簡単なネットワークを示しています。 このシナリオでは、ホストAとEが、Nagiosを実行していて、示されたすべてのホストを監視しているとします。 ホストAは「マスター」ホストであると考えられます、そして、ホストEは「スレーブ」ホストであるとします。
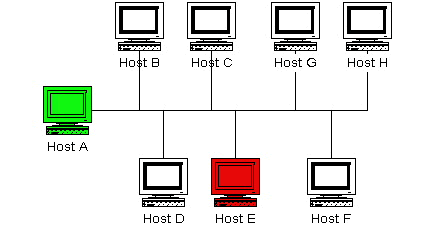
初期プログラム設定
スレーブホスト(ホストE)は初期設定の enable_notificationsi 指示が無効になっています。そのためホストやサービスの通知は行われません。 同様にスレーブホストは check_external_commands 指示を有効にしておきます。 これらの設定は簡単でしょう…
初期設定
次に、私たちは、マスターとスレーブホストに関するオブジェクト設定ファイルの違いを考える必要があります…
上の図の全ホストの監視をマスターホスト(ホストA)が行う設定を行ったと仮定します。 スレーブホスト(ホストE)は同じサービスとホストの監視設定を設定ファイルに次のように追加して行う必要があます…
- ホストA(ホストE設定ファイルの)のホスト定義には、ホストイベントハンドラを定義する必要があります。 このイベントハンドラの名前はhandle-master-host-eventということにします。
- ホストEの設定ファイルにホストAのNagiosプロセスを監視するためのサービス定義を記述します。これは check_nagiosプラグインをホストA上で動かすということと仮定します。これはiこのFAQの通りにやれば良いでしょう(これをアップデートします!)。
- ホストAのNagiosプロセスチェックのサービス定義にイベントハンドラを設定します。 このイベントハンドラの名前はhandle-master-proc-eventとしておきます。
重要な点としては、ホストA(マスターホスト)はホストE(スレーブホスト)の状態は知らなくても良いということです。 このシナリオでは単純にその必要がありません。 もちろん、ホストAからホストEの監視を行いたければやってもかまいませんが、冗長構成にはなんの影響も与えません…
イベントハンドラ・コマンド定義
スレーブホスト上に次のようなイベントハンドラをコマンド定義に記述するためちょっと時間を割く必要があります。 ここに、例があります…
define command{
command_name handle-master-host-event
command_line /usr/local/nagios/libexec/eventhandlers/handle-master-host-event $HOSTSTATE$ $HOSTSTATETYPE$
}
define command{
command_name handle-master-proc-event
command_line /usr/local/nagios/libexec/eventhandlers/handle-master-proc-event $SERVICESTATE$ $SERVICESTATETYPE$
}
イベントハンドラ・スクリプトを /usr/local/nagios/libexec/eventhandlers ディレクトリに置くという前提になっています。 置き場所は好きなところで結構ですが、私がここに出した例を変更する必要があります。
イベントハンドラ・スクリプト
では、次のようなイベントハンドラ・スクリプトについて見ていきましょう・・・。
ホスト・イベントハンドラ(handle-master-host-event):
#!/bin/sh
# Only take action on hard host states...
case "$2" in
HARD)
case "$1" in
DOWN)
# The master host has gone down!
# We should now become the master host and take
# over the responsibilities of monitoring the
# network, so enable notifications...
/usr/local/nagios/libexec/eventhandlers/enable_notifications
;;
UP)
# The master host has recovered!
# We should go back to being the slave host and
# let the master host do the monitoring, so
# disable notifications...
/usr/local/nagios/libexec/eventhandlers/disable_notifications
;;
esac
;;
esac
exit 0サービス・イベントハンドラ(handle-master-proc-event):
#!/bin/sh
# Only take action on hard service states...
case "$2" in
HARD)
case "$1" in
CRITICAL)
# The master Nagios process is not running!
# We should now become the master host and
# take over the responsibility of monitoring
# the network, so enable notifications...
/usr/local/nagios/libexec/eventhandlers/enable_notifications
;;
WARNING)
UNKNOWN)
# The master Nagios process may or may not
# be running.. We won't do anything here, but
# to be on the safe side you may decide you
# want the slave host to become the master in
# these situations...
;;
OK)
# The master Nagios process running again!
# We should go back to being the slave host,
# so disable notifications...
/usr/local/nagios/libexec/eventhandlers/disable_notifications
;;
esac
;;
esac
exit 0
これが私たちのためにすること
スレーブホスト(ホストE)は初期状態では通知は無効で、マスターホスト(ホストA)のNagiosプロセスが有効である間はどんなホスト、サービス通知も発しません。
スレーブホスト(ホストE)の上のNagiosプロセスはいつマスターホストになるか。
- マスターホスト(ホストA)が停止し、 handle-master-host-event が実行された時。
- マスターホスト(ホストA)のNagiosプロセスが停止し、 handle-master-proc-event サービス・イベントハンドラが実行された時。
スレーブホスト(ホストE)の上のNagiosプロセスで通知を可能にするとき、それは、どんなサービスや、ホストの障害や復旧に関する通知も送ることができます。 ここで、事実上、ホストEはホストとサービスの連絡先設定を引き継ぎました!
ホストEの上のNagiosプロセスはいつスレーブホストに戻るか。
- ホストAが復旧し handle-master-host-event ホストイベントハンドラが実行された時。
- ホストAのNagiosプロセスが復旧しhandle-master-proc-eventが実行された時。
ホストEのNagiosプロセスで通知を無効にするとき、それは、どんなサービスや、ホストの障害や復旧に関する通知は送られなくなります。 この段階で、ホストEはホストAに連絡先を送る権限を受け渡したと言うことになります。すべてが最初の状態に戻ったということになります!
タイムラグ
Nagiosの冗長系は決して完全ではありません。 その問題の1つに、マスターホストが停止してスレーブホストに移行するまでのタイムラグが挙げられます。これは以下で影響を受けます…
- マスターホストの停止とスレーブホストが問題を検出する1回目の間の時間
- マスターホストが障害発生したか検証する必要のある時間 (スレーブホストがサービスやホストチェックを再試行している時間)
- イベントハンドラの実行と次のNagiosからの外部コマンドのチェックまでの間の時間
これらのタイムラグを最小限に抑えるには…
- ホストEのNagiosプロセス(再)チェックを1回にするか、もっとも頻繁に行う設定にする。 この設定はサービス定義のcheck_intervalとretry_intervalオプションで行います。
- (ホストE)上のホストAのホストチェックの数を素早いホスト障害検知を可能にする設定にする。これはホスト定義のmax_check_attempts引数で設定します。
- メイン設定ファイルのcommand_check_intervalオプションで設定することによってホストE上の外部コマンドチェックの頻度を上げる。
また、NagiosがホストAの上で回復するとき、ホストEがスレーブホストに戻る前に、何らかのタイムラグあります。 これは以下で影響を受けます…
- ホストAの回復とホストEの上のNagiosプロセスが回復を検出する間の時間
- ホストBにおけるイベントハンドラの実行とホストE上のNagiosプロセスが外部コマンドがないかどうかチェックする間の時間
Nagiosが監視権限を移行する際の実際のタイムラグは定義したサービスの数にとても依存しています、サービスチェックの間隔や単純に偶然性など。 いずれにせよ、それは確実にないよりましです。
特別なケース
ここで一つ知っておくべき事があります… もしホストAが停止した場合、ホストEは障害通知を有効にし、通知を送る責任を引き継ぎます。ホストAが復旧した時、ホストEは通知が無効になります。 もし、- ホストAが復旧した時 - ホストAのNagiosプロセスが適切に起動しなかったら、どちらのホストも連絡先が有効にならない時間ができるでしょう! 幸い、Nagiosのサービスチェックロジックはこれを解決できます。 次に、ホストEのNagiosプロセスがホストAのNagiosプロセスをチェックする際にホストAのNagiosプロセスが稼働していないことを検知するでしょう。 ホストEは、再び通知を有効にし、通知を引き継ぎます。
どちらのホストもネットワークを監視しない正確な時間は決定しにくいです。 監視していない時間を極力短くすることは(ホストE上で)ホストAのNagiosプロセスを監視する頻度を増やすことで極力短くすることで可能であること は明白です。あと考えられるのは単純な偶然によるものですが、この"ブラックアウト"した合計時間をあまり気にしてはいけません。
シナリオ2-- 監視のフェイルオーバー化
序論
監視のフェイルオーバー化も(上のシナリオ 1で述べた)監視の冗長系とよく似ていますが、わずかに異なります。
Goals 目標
監視のフェイルオーバー化の基本的な目的は、マスター・ホストのNagiosプロセスが稼働している際は、スレーブホストのNagiosプロセスはアイドル状態にしておく事にあります。 マスターホストのプロセスが(ホストの停止などで)停止した場合に、スレーブホストが監視を開始するようにするということです。
シナリオ 1 で述べた、マスター監視ホストが停止した場合、通知設定を引き継ぐやり方にはいくつかの落とし穴があります。 その最大の問題点は、マスターと同じ時間に同じホストやサービスをスレーブホストが監視していると言うことです! これはもし多数のサービスを定義していたら過度のトラフィックや負荷を引き起こす原因になる可能性があります。 ここに、その問題を回避する方法があります…
初期プログラム設定
スレーブホストのexecute_service_checksとenable_notifications指示でアクティブ・チェックと通知を無効にします。 これによって、マスターホストの上のNagiosプロセスが活動している間、スレーブホストは、ホストとサービスを監視して、通知を出すことができません。 スレーブホストでは check_external_commands指示を有効にしているか確認するのを忘れないようにしてください。
マスター・プロセス・チェック
スレーブホスト上でマスターホストのNagiosプロセスをチェックするスクリプトをcronジョブとしてもっとも頻繁に(1分毎)に設定します(マスターのNagiosプロセスの監視にはマスターホストでnrpe デーモンとcheck_nagiosを使いスレーブホストでcheck_nrpeプラグインを走らせます)。 そのスクリプトは check_nrpe pluginから帰ってくるリターンコードをチェックします。もしリターンコードがnon-OKステートなら、そのスクリプトが外部コマンドファイルに通知とアクティブ・サービス・チェックを有効にするように書き込みます。 もしプラグインがOKステートを返したなら、そのスクリプトは外部コマンドファイルに通知とアクティブ・チェックを無効にするよう書き込みます。
そうすれば、一度のサービス・ホスト監視に1つのプロセスだけがチェックすることになり、すべてを2回行うより遙かに効率的です。
注意は、ものが異なって扱われるので、シナリオ1のように、ホストとサービス・ハンドラを定義する必要はありません。
追加設定
ここで、非常に基本的なフェイルオーバー監視設定の実装をしました。 しかしながら、事態をスムーズに行うために考慮すべき点が1つあります。
これまでの設定方法での最大の問題点は監視を引き継ぐ際に現在のホスト・サービスの状態は引き継がない点にあります。 この問題を解決する1つの方法は、nsca addonを使用することでマスターホストで ocspコマンド を可能にして、すべてのサービス・チェック結果をスレーブホストに送らせることです。 これによりスレーブホストは常に最新の監視ステータスを持つことが可能になります。 スレーブホスト上ではアクティブ・サービス・チェックが無効になっているので、どんなサービス・チェックも実行されません。 しかし、必要ならホストチェックしましょう。 これはマスターとスレーブのホストチェックが必要だという事を意味し、監視の大部分はサービス・チェックなのでたいした影響はありません。
設定に関してはおおよそこのくらいです。