
序論
ネットワークサービスとリソースの分散監視をサポートするためにNagiosを設定できます。 ここではその方法について簡潔に説明します…
目標
ここで記述する分散監視環境の目的の一つは"中央"サーバから1つ以上の"分散された"サーバでサービスチェックを行うことで(CPU使用率などの)オーバーヘッドを軽減させることにあります。 ほとんどの小・中規模の環境ではこのような設定を行う必要は無いでしょう。 しかし、100または1000のホスト(と多くのサービス)をNagiosで監視しようと思うと、分散監視はとても重要になってきます。
参照図
以下の図は、分散監視がNagiosと共にどう働くかに関する概念を理解するのを助けるはずです。 この図中の絵を使いながら説明していきます…。
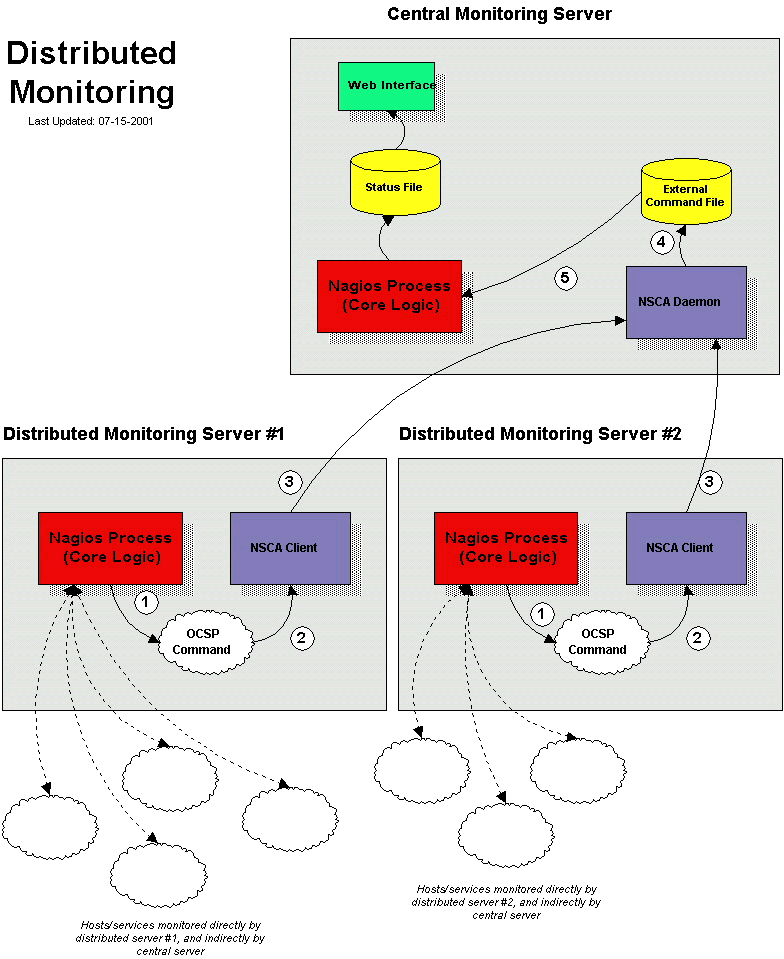
集中サーバー対分散サーバ
Nagiosで分散監視環境を設定する際は、中央サーバと分散サーバは異なる方法で設定します。 これからどのように双方のタイプのサーバを設定するのか、その設定が監視全体にどのような変化をもたらすのかについて説明します。 まず始めに、異なるタイプのサーバの目的について説明します。
分散サーバの機能は定義したホストの"クラスタ"の全サービスをアクティブ・チェックすることです。 ここで使う"クラスタ"の意味は広義に使用しています - 基本的にはネットワーク上の任意のホストのグループを示しています。 ネットワーク環境に依存しますが、1つの場所にいくつかのクラスタがあるでしょう。また、それらのクラスタはWANやファイアウォールなどで分割されているかもしれません。 (任意に定義した)それぞれのクラスタホストで覚えておくべき重要なことは、そのクラスタ内でNagiosを稼働し、ホストのサービスを監視している分散サーバは1つであるということです。 1つの分散サーバは通常Nagiosのベアボーン・インストールします。 分散サーバは望まない限り、ウェブインタフェイスをインストールする必要もなく、通知やイベントハンドラも必要なく、どんなサービスチェックもする必要がありません。 分散サーバ設定のより詳しい説明は後で行います…
中央サーバの役割は、1つ以上の分散サーバからのサービスチェックの結果を単純に聞くことです。 サービスはときどき中央サーバからアクティブ・チェックされますが、このアクティブ・チェックは緊急時にのみ行われるもので、殆どはパッシブ・チェックを受けるだけです。 中央サーバは1つ以上の分散サーバからのパッシブ・サービス・チェックの結果を受け取るので、中央サーバは全監視ロジックが焦点となります。 (通知、イベントハンドラ・スクリプトの起動、ホスト状態の決定、ウェブインタフェイスを提供する、等々)
分配された監視からサービス・チェック情報を得ます。
それでは、どのようにして分散サーバから中央サーバへサービスチェックの結果を送っているのか知るために設定の詳細へ進みましょう。すでにNagiosが 稼働しているホストでどのようにしてパッシブ・チェックの結果を受け取るかについては説明しています(パッシブ・チェック・ドキュメントを参照してくださ い)。しかし、他のホストからのパッシブ・チェックを受け取る方法については情報を提供していません。
パッシブ・チェックの結果をリモート・ホストへ送るために、私はnscaアドオンを書きました。 このアドオンには2つのプログラムで構成されています。 一つは、リモートホストで動き、他のサーバへサービス・チェックの結果を送信するクライアントプログラム(send_ncsa)。 2つ目はスタンドアロン・デーモンまたはinetd経由で動きクライアントプログラムからのコネクションを待つncsaデーモン(nsca)です。クライ アントからサービスチェック情報を受け取ることで、デーモンはPROCESS_SVC_CHECK_RESULTコマンドにて(中央サーバの) Nagiosの 外部コマンドファイルにチェック情報を登録します。 次にNagiosが外部コマンドをチェックし、分散サーバが処理し、送信したパッシブ・サービス・チェックの情報をみつけます。 簡単、えっ?
分散サーバ設定
じゃぁ実際の分散サーバのNagiosの設定は? 基本的に、それはインストールの要点です。 ウェブ・インタフェースや通知は必要ありません。これらの機能はは中央サーバに持たせます。
主要な設定変更:
- オブジェクト設定ファイルにその分散サーバが直接監視するホストとサービスを定義します。
- 分散サーバのenable_notificationsを0に設定します。 これはこのサーバからどんな通知も送らないという設定です。
- 分散サーバにはobsess over サービスの設定を行います。
- 分散サーバには ocsp コマンドを定義します(以下で説明されるように)。
すべてを共に正しく稼働させるためには、分散サーバはすべてのサービスチェックを Nagiosに送ることを期待していす。 イベントハンドラを使えば状態の変化をレポートすることが出来ますが、それだと中断できません。 強制的に分散サーバにすべてのサービス・チェックの結果を送信させるには、メイン設定ファイルのobsess_over_servicesを有効にし、サービスチェックの後に毎回 ocsp_command を実行させなくてはならりません。 中央サーバへ全サービスチェックの結果を送るために(上で説明した) send_nscaクライアントと nscaデーモンを使ったocspコマンドを使用します。
設定を完了するために、以下のようなocspコマンドを定義する必要があります:
ocsp_command=submit_check_result
submit_check_result コマンドのコマンド定義はこの様に見えます。
define command{
command_name submit_check_result
command_line /usr/local/nagios/libexec/eventhandlers/submit_check_result $HOSTNAME$ '$SERVICEDESC$' $SERVICESTATE$ '$SERVICEOUTPUT$'
}The submit_check_result shell scripts looks something like this (replace central_server with the IP address of the central server):
#!/bin/sh
# Arguments:
# $1 = host_name (Short name of host that the service is
# associated with)
# $2 = svc_description (Description of the service)
# $3 = state_string (A string representing the status of
# the given service - "OK", "WARNING", "CRITICAL"
# or "UNKNOWN")
# $4 = plugin_output (A text string that should be used
# as the plugin output for the service checks)
#
# Convert the state string to the corresponding return code
return_code=-1
case "$3" in
OK)
return_code=0
;;
WARNING)
return_code=1
;;
CRITICAL)
return_code=2
;;
UNKNOWN)
return_code=-1
;;
esac
# pipe the service check info into the send_nsca program, which
# in turn transmits the data to the nsca daemon on the central
# monitoring server
/bin/printf "%s\t%s\t%s\t%s\n" "$1" "$2" "$return_code" "$4" |
/usr/local/nagios/bin/send_nsca -H central_server -c /usr/local/nagios/etc/send_nsca.cfg 上のスクリプトが、/usr/local/nagios/bin/と/usr/local/nagios/etc/ それぞれのディレクトリにある設定ファイル(send_nsca.cfg)にsend_nscaプログラムがあるとします。
それです! これでリモートホストで稼働しているNagiosを分散監視サーバとして設定できました。では実際に分散サーバの挙動とどのようにNagiosへサービスチェックの結果を送っているのか見てみましょう(下の順番の番号は上の図の番号に対応しています)。:
- 分散サーバが、サービス・チェックを実行し終えた後、ocsp_command変数で定義したコマンドを実行します。 ここの例では、/usr/local/nagios/libexec/eventhandlers/submit_check_resultスクリプトになります。 submit_check_resultコマンドの定義は4つの情報をスクリプトに引き渡すことに注目してください: サービスが関連しているホストの名前、サービス記述、サービスチェックからのリターンコード、およびサービスからのプラグイン出力をチェックします。
- submit_check_resultスクリプトがサービス・チェック情報(ホスト名、説明、リターンコード、出力)を send_nscaクライアントへパイプします。
- send_nscaが中央監視サーバのnscaデーモンにサービス・チェック情報を転送します。
- 中央サーバのnscaデーモンがサービス・チェック情報を受け取り、Nagiosが後で取り出す外部コマンド・ファイルに書き出します。
- 中央サーバのNagiosプロセスが外部コマンド・ファイルを読み、外部監視サーバからのパッシブ・サービス・チェック情報を処理します。
集中サーバー設定
ここまでで分散サーバの設定を見てきました。次に中央サーバに移りましょう。集中させるためには、中央サーバーは通常設定するようなスタンドアロンサーバのような設定を行います。 その設定方法は次のようになります:
- 中央サーバーで、ウェブ・インタフェースをインストールします。 (オプションですがお勧めです)
- 中央サーバは enable_notifications示を1に設定します。 これは通知を有効にします。 (オプションですがお勧めです) 中央サーバではアクティブサービスチェックを無効にします。 (任意であるが、お勧め--、以下での注意参照)
- 中央サーバでは外部コマンドチェックを有効にします (必要)
- 中央サーバではパッシブサービスチェックを有効にします。 (必要)
中央サーバーを設定するとき、覚えておく必要がある3つの非常に重要なことがあります:
- 中央サーバーには、すべての分散サーバによって監視されているすべてのサービスのためのサービス定義がなければなりません。 Nagiosはサービス定義で定義されていないパッシブ・チェックの結果を無視します。
- もし中央サーバを分散サーバからの結果を処理するためだけに使用するのであれば、全アクティブ・チェックをプログラム全体に無効にするexecute_service_checks指示を単純に0に設定することができます。 もし中央サーバでもいくつかのサービスをアクティブ・チェックさせるのであれば、分散サーバが受け持つサービス定義のenable_active_checksオプションを0に設定します。 これは、Nagiosがアクティブ・サービス・チェックするのを防ぎます。
プログラム全体に全サービスをもしくは分散サーバが監視するサービスにはenable_active_checksオプションでサービス・チェックを無効にすることは重要です。これはアクティブ・サービス・チェックが通常の状況で絶対実行されないようにする設定です。 そのサービスは通常のチェック間隔(3分毎、5分毎など・・)で再スケジュールされ続けますが、実際には実行されません。 この再スケジュールのループはNagiosが稼働している間、単に続けられるというだけです。 なぜかと言うことに関して少しだけ説明しましょう…
それです! 簡単、えっ?
パッシブ・チェックに関する問題
すべての集中監視のために中央サーバはパッシブ・チェックに頼っていると言えます。 完全に監視をパッシブ・チェックに頼るということの主な問題点はNagiosは監視情報を他の何かから提供されることに頼らなければならないという事実です。 パッシブ・チェックの結果を送るリモートホストが、停止、またはunreachableになると、どうなるでしょうか? Nagiosがそのホストのサービスにアクティブ・チェックを行っていない場合、どうやってその問題を検知すればいいでしょう?
幸い、これらのタイプの問題を扱うことができる方法があります…
新鮮さチェック
Nagiosはサービスチェックの結果を"新鮮さ"チェックする機能があります。 新鮮さチェックのより詳しい情報はこちらにあります。 この機能はリモート・ホストが中央サーバへパッシブ・チェックの結果を送ってこなくなったという状況から保護します。"フレッシュネス"チェックのその目 的は分散サーバから送られるパッシブ・サービス・チェックと中央サーバ上の通常のアクティブ・チェックの結果を確実にすることです。 もし分散サーバからのサービス・チェックの結果が"期限切れ"状態であったら、Nagiosは中央監視サーバから強制的にそのサービスをアクティブ・チェックするよう設定します。
それで、どのようにしますか? 分散サーバで監視をするサービスに中央サーバで次のように設定します…
- サービス定義のcheck_freshnessオプションを1に設定します。 そのサービスの"新鮮さ"チェックを有効にします。
- サービス定義のfreshness_thresholdオプションに(分散サーバから送られてくる)サービス・チェックの結果がどれぐらい"新鮮"かの値を設定します(秒単位)。
- サービス定義のcheck_commandオプションに中央サーバからのアクティブ・サービス・チェック用のコマンドを設定します。
Nagiosは新鮮さチェックが有効になっている全サービスの結果を定期的に"新鮮"かどうかチェックします。 それぞれのサービス定義のfreshness_thresholdの値がサービス・チェックの結果が"新鮮"かどうか判断する基準になります。 例えば、あるサービスのこの値を300に設定したとしたら、Nagiosはサービス・チェックの結果が3分(300秒)より古ければそれは"期限切れ"と考えます。 freshness_thresholdオプションの値を設定しない場合、Nagiosはnormal_check_intervalもしくはretry_check_intervalオプションのどちらかから自動的に"フレッシュ"かどうか計算します(計算値はそのサービスがどんな ステートタイプ かに依存します)。 もしそのサービスチェックの結果が"期限切れ"であったならば、Nagiosはそのサービスのサービス定義のcheck_commandオプションで指定したサービス・チェックを実行します。 、その結果、アクティブ・サービス・チェックをします。
中央サーバからそのステータスをアクティブ・チェックできるようにサービス定義の check_commandオプションを指定しなくてはならないことを覚えておいてください。通常、このチェックコマンドは実行されることはありません (なぜならそのサービスはプログラム全体もしくはその特定のサービスでアクティブ・チェックが無効にしているから)。 新鮮さチェックが有効の際は、Nagiosはもしプログラム全体およびその特定のサービスでアクティブ・チェックが無効になっていたとしてもそのサービスのステータスをこのコマンドでアクティブ・チェックします。
もし、中央監視サーバからのアクティブ・チェック・コマンドを定義できない場合 (もしくは設定することが困難だと判明した場合)、全サービスの check_commandオプションに単純に警告ステータスを返すダミースクリプトを設定します。 ここに、例があります… 定義するコマンド名を 'service-is-stale'としてサービス定義のcheck_commandに設定することを想定しています。 定義は次のような感じです…
define command{ command_name service-is-stale
command_line /usr/local/nagios/libexec/check_dummy 2 "CRITICAL: Service results are stale"
}
Nagiosがサービス結果が停滞していることが分かると、service-is-staleコマンドであるcheck_dummyプラグインを実行しサービスをCRITICAL状態にします。 これでおそらく通知を出すでしょう、それで問題があるのを認知します。
ホスト・チェックを実行します。
ここまでで分散サーバからパッシブ・サービス・チェックを行う方法を学びました。 これは、中央サーバがアクティブ・サービス・チェックを行わないことを意味します。 しかし、ホスト・チェックはどうですか? まだそれらをする必要があるので、どのようにですか?
ホストチェックは監視活動の中では通常妥協できる点(絶対に必要というわけでなければ)ですので中央サーバからのアクティブ・チェックで良いかと思いま す。つまり、つまり分散サーバで行っているのと同じように(非分散監視環境の時と同じように)中央サーバにもホス・トチェックの設定をします。
パッシブ・ホスト・チェックも可能です(ここを見てください) 。分散監視設定で使えますが、少し問題があります。 最も大きい問題は、それらが処理されるとき、Nagiosがパッシブ・ホストチェック問題ステータス(DOWNとUNREACHABLE)を理解しないと いうことです。 あなたの監視サーバーが異なる親/子ホスト構造(監視サーバは異なる場所にあります)を備えている場合、中央監視サーバにホスト・ステータスが不正確に見えることを意味します。
分散監視サーバから中央監視サーバへパッシブ・チェックを送信したければ、次の事を確実に行ってください :
- 中央サーバーで、パッシブ・ホスト・チェックを有効にします。(必要)
- 分散監視サーバはobsess over hostsが設定されている。
- 分散監視サーバにochp command定義がされている。
ochpコマンドはホストチェック結果を処理するのに使用し、サービスチェック結果を処理するocspコマンドと同じように使います(上述のドキュメントを見て下さい)。 パッシブ・ホスト¥チェック結果が確実に最新になるようにする為、ホストの freshness checking を有効にする必要があります (サービスについて上述されているものと方法は同じです)。