
序論
Nagiosはオプションでホストとサービスの"バタツキ"を検知する機能があります。 バタツキはホストやサービスの状態が頻繁に変化し、障害と復旧の通知の嵐になったときに発生します。 バタツキは設定の問題(閾値が低すぎるとか)もしくは実際のネットワーク障害を示すことができます。
バタツキ検知はどう働いているか。
説明に移る前に、バタツキ検知機能を実装するのは困難だったと言わざるを得ません。 人は、どのようにしてホストやサービスの状態変化が「あまりに頻繁」であると決めればいいですか? バタツキ検知の最初に実装を始める際に、どのようにバタツキを検知できる/すべきかいくつかの情報を見つけようとしました。 私は、他が使っていたものに関する少しの情報も見つけることができませんでした(そこで何を使用してでも彼ら?)、私が私に理にかなった解決であるようだったことで落ちつくことに決めました...
Nagiosがホストかサービスの状態をチェックする場合は常に、それは、バタツキを始めたか止めたかどうかチェックするでしょう。 それは以下でこれをします。
- ホストまたはサービスの21回のチェック結果を格納します。
- 過去のチェック結果を分析して、状態変化/変遷がどこに起こるかを決定します。
- ホストやサービスのために、状態変化率(変化の測定)を測定するのに状態遷移を使用します。
- バタツキ閾値の上限下限に状態変化率のパーセントを比較します。
状態変化率が最初に高いバタツキ閾値を上回るとき、ホストまたはサービスはバタツキを始めたと決定しています。
ホストかサービスのバタツキが状態変化率の閾値を下回る場合は(それを仮定するのは以前に、ばたついていました)、バタツキが止まったと判断します。
例
サービスのバタツキ検知がどう働いているかを詳細に説明しましょう…
下記の画像は、ごく最近の21のサービスチェックから、サービス状態の履歴を示します。 OKステートは緑、WARNINGステートは黄色、CRITICALステートは赤で、UNKNOWNステートはオレンジです。
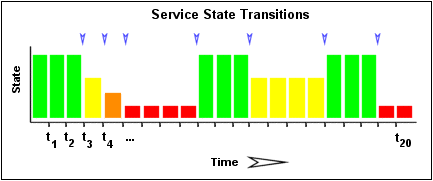
過去のサービスチェック結果は、状態変更/変遷がどこで起こるかを決定するために調べられます。 格納された状態がその直前に格納された状態と異なっているとき、状態変化は起こります。 配列内に過去21個のサービスチェックの結果が保存されているので、配列内には20個のステート変化が入る可能性があります。 この例には、青い矢によって示された、7回の状態変化があります。
バタツキ検知ロジックは、サービスのために全体的な状態変化率を決定するために、状態の変化を使用します。 これはサービスの不安定/変化の測定です。 サービスは、状態変化値が 0% の時、絶対状態を変化させない。 しかしながらサービスは、 100% 状態変化のチェックが行われた時は状態変化が起こります。 ほとんどのサービスは状態変化率の中間をどこかに持ちます。
サービスのために状態変化率を計算するとき、バタツキ発見アルゴリズムは状態変化が古いものより新しい状態変化に多くの重さ付けをします。 はっきり、バタツキ検知ルーチンは、古い可能な状態変化より50% 以上の重さで可能な最新の状態変化が起こる様に現在設計されている。 以下の図で特定のサービスのステート変化率を計算する際に古いステート変化より最近の状態変化の重さをどのように与えているかを示しています。
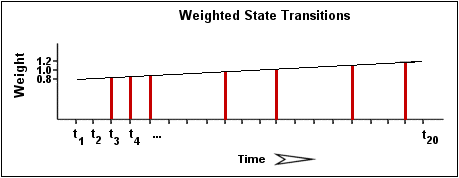
イメージを使用して、サービスの状態変化率の計算をさせます。 合計7回の状態変化(t3, t4, t5, t9, t12, t16, and t19) が見られます。 時間がたつにつれての状態変更の少しも重さがなければ、これは35%の総状態変更を私たちに与えるでしょう:
(20回ぐらいのステート変化中7回変化) *100 = 35%
バタツキ検知ロジックがより新しい状態変更に古い状態変更より高い割合を与えるので、実際の計算された状態変化率はこの例においてわずかに35%未満になるでしょう。 発生時間によるウエイトを加えた状態でのステート変化率は31%であると言えるでしょう。
計算されたサービスのパーセント変化(31%)は、次に何が起こるかを確認するバタつき閾値と比較されます。
- サービスが以前にバタツキしておらず、バタツキ閾値の31%を超えた場合、Nagiosは、サービスが、バタツキを開始したと考えます
- サービスが以前にバタツキしていて、バタツキ閾値の31%を下回った場合、Nagiosは、サービスが、バタツキを停止したと考えます
この2つの条件いずれもマッチしない場合、そのサービスは現在もバタツキしているか、バタツキしていないかのいずれかなので、Nagiosは何もしません。
サービスのためのバタツキ検知
Nagiosは、サービスがチェックされる(アクティブまたはパッシブ)ときはいつでも、サービスがバタツキしているかどうか見るためにチェックします。
サービスのためのバタツキ検知ロジックは、上記の例で説明されるように、働いています。
ホストのためのバタツキ検知
ホストバタツキ検知は1つの重要な違いを除いてサービスバタツキ検知と同じような感じで働きます: Nagiosが、ホストがバタツキしているかどうかチェックを試みます:
- ホストはチェックされます。 (アクティブまたはパッシブ)
- サービスがホストがチェックされた時と関連している時々 もっとはっきりと、最後のバタツキ検知が実行されてから 少なくとも x 時間経過し、ホストに関連した全てのサービスチェック間隔の平均が x と等しい場合
これはなぜ完了していますか? サービスで、私たちは、連続したバタツキ検知ルーチンの間の最小の時間がサービスチェック間隔と等しくなるのを知っています。 しかし、あなたは定期的にホストを監視していないかもしれないので、バタツキ検知ロジックで使われることができるホストチェック間隔がないかもしれません。 また、サービスをチェックすることがホストのバタツキの発見にプラスにならなければならないことは、意味があります。 サービスは結局ホストに関連した事柄の属性です。 いずれにせよ、どれくらいの頻度でバタツキ検出をあなたのホストに実行できたかで決定めるのが最も良い方法です。
バタツキ検知閾値
Nagiosは、幾つかの値を使ってパーセント状態閾値を決定します。それはバタツキ検出に使われます。 ホストとサービスの両方のために、グローバルな上限、下限の閾値とホスト特有またはサービス特有の閾値を設定できます。 ホストやサービスに特定の閾値を指定しない場合、Nagiosはバタツキ検知にグローバルな閾値を使用します。
下記のテーブルは、バタツキ検知の中で使用される様々な閾値をコントロールする、グローバル変数、ホストまたはサービスに特有の変数を示します。
バタツキ検出の為のステータス
チェック結果(ホスト/サービス状態)に関係なく、バタツキ検知ロジックのために、通常、Nagiosはホストまたはサービスの最後の21回のチェックの結果を行います。
 あなたのホストまたはサービス定義でflap_detection_options指示を用いてバタツキ検知ロジックで特定のホストまたはサービス状態で使用しないことができます。
すなわち、あなたがこの指示であなたはバタツキ検知を使いたい(UP,DOWN,OK,CRITIAL)ホストとサービス状態を指定する事ができます。
この指示を使用しない場合、すべてのホストやサービス状態がバタツキ検知に使用されます。
あなたのホストまたはサービス定義でflap_detection_options指示を用いてバタツキ検知ロジックで特定のホストまたはサービス状態で使用しないことができます。
すなわち、あなたがこの指示であなたはバタツキ検知を使いたい(UP,DOWN,OK,CRITIAL)ホストとサービス状態を指定する事ができます。
この指示を使用しない場合、すべてのホストやサービス状態がバタツキ検知に使用されます。
バタツキの取り扱い
サービスやホストのバタツキを最初に検知した時、Nagiosは次のことを行います:
- そのサービスやホストがバタツキしたことをログに書き出します。
- そのサービスやホストがバタツキしたことを保存されないコメントに追加します。
- ホストやサービスの連絡先のために、「バタツキ開始」の通知を送ります。
- そのサービスやホストの通知を停止します(これが通知ロジックの最初のフィルタです)。
サービスやホストがバタツキを停止した際、Nagiosは以下のことを行います:
- そのサービスやホストがバタツキを停止したことをログに書き出します。
- バタツキが始まったときに記録したコメントを消去します。
- ホストやサービスの連絡先のために、「バタツキ停止」の通知を送ります。
- サービスやホストのために通知の停止を取り外します(通知はそれでも、通常の通知ロジックがおこないます)。
バタツキ検出を可能にします。
Nagiosでバタツキ検知機能を有効にするために、以下のことが必要です。
- enable_flap_detection 指示に、1をセットします。
- ホストとサービス定義におけるflap_detection_enabled指示に1を設定します。
全体でバタツキ検知を無効にしたいなら、enable_flap_detection 指示に0をセットします。
ホストやサービスのバタツキ検知を無効にしたいなら、ホスト/サービス定義のflap_detection_enabled 指示を使います。
 参照: 状態タイプ
参照: 状態タイプ