
Einführung
Nagios unterstützt die Erkennung von Hosts und Services, die "flattern". Flattern tritt auf, wenn Hosts oder Services zu oft den Zustand wechseln und dadurch einen Sturm von Problemen und Erholungsbenachrichtigungen erzeugen. Flattern kann auf Konfigurationsprobleme hinweisen (z.B. Schwellwerte, die zu niedrig gesetzt sind), störende Services oder wirkliche Netzwerkprobleme.
Wie die Flatter-Erkennung arbeitet
Bevor ich darauf eingehe, lassen Sie mich sagen, dass es etwas schwierig war, Flatter-Erkennung zu implementieren. Wie genau legt man fest, was "zu häufig" in Bezug auf Statusänderungen für einen Host oder Service ist? Als ich zuerst an die Implementierung der Flatter-Erkennung gedacht habe, versuchte ich Informationen zu finden, wie Flattern erkannt werden könnte/sollte. Ich konnte keinerlei Informationen darüber finden, was andere benutzten (benutzen andere so etwas?), also entschied ich mich für das, was ich für eine sinnvolle Lösung hielt...
Sobald Nagios den Zustand eines Hosts oder Services prüft, wird es prüfen, ob dafür Flattern begonnen oder geendet hat. Es tut dies durch:
- speichern der Ergebnisse der letzten 21 Prüfungen des Hosts oder Service
- analysieren der historischen Prüfergebnisse und feststellen, wo Statusänderungen/-übergänge auftreten
- benutzen der Statusübergänge, um einen Statuswechsel-Prozentsatz (ein Maß für die Änderung) für den Statuswechsel des Hosts oder Service festzulegen
- vergleichen des Statuswechsel-Prozentwertes gegen die Flatter-Schwellwerte (hoch und niedrig)
Ein Host oder Service wird angesehen, mit dem Flatter begonnen zu haben, wenn der Prozentsatz das erste Mal einen hohen Flatter-Schwellwert überschritten hat.
Ein Host oder Service wird angesehen, das Flattern beendet zu haben, wenn der Prozentsatz unter einen niedrigen Flatter-Schwellwert sinkt (vorausgesetzt, dass er vorher geflattert hat).
ein Beispiel
Lassen Sie uns etwas detaillierter beschreiben, wie Flatter-Erkennung bei Services arbeitet...
Das Bild unten zeigt eine chronologische Historie von Service-Zuständen der letzten 21 Service-Prüfungen. OK-Zustände sind in grün dargestellt, WARNING-Zustände in gelb, CRITICAL-Zustände in rot und UNKNOWN-Zustände in orange.
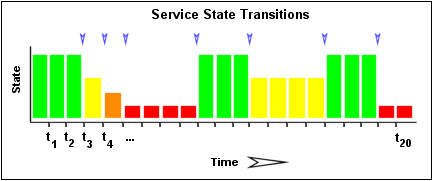
Die historischen Service-Prüfergebnisse werden untersucht, um festzustellen, wo Statusänderungen/-übergänge auftreten. Statusänderungen treten auf, wenn ein archivierter Status sich von den archivierten Zuständen unterscheidet, die ihm direkt vorausgehen. Da wir die Ergebnisse der letzten 21 Status-Prüfungen in dem Array ablegen, können wir bis zu 20 Statusänderungen haben. In diesem Beispiel gibt es sieben Statusänderungen, die im Bild durch blaue Pfeile gekennzeichnet sind.
Die Flatter-Erkennungslogik nutzt die Statusänderungen, um einen Gesamtprozentsatz für den Service festzulegen. Dies ist ein Maßstab für die Sprunghaftigkeit/Änderung des Service. Services, die nie den Status wechseln, haben einen Statusänderungswert von 0%, während Services, die ihren Status bei jeder Prüfung wechseln, einen Wert von 100% haben. Die meisten Services werden einen Prozentwert irgendwo dazwischen haben.
Während der Berechnung des Prozentsatzes für den Service wird der Flatter-Erkennungsalgorithmus mehr Gewicht auf neuere Statusänderungen legen als auf alte. Genauer gesagt sind die Flatter-Erkennungsroutinen im Moment so ausgelegt, dass der neueste Statuswechsel 50% mehr Gewicht hat als der älteste. Das Bild unten zeigt, wie neuere Statuswechsel mehr Gewicht erhalten als ältere, während der Gesamtprozentwert für einen bestimmten Service berechnet wird.
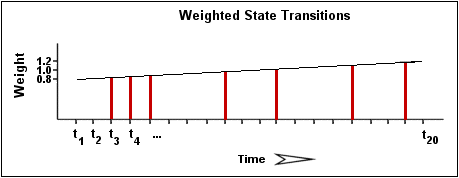
Lassen Sie uns mit dem obigen Bild eine Berechnung der prozentualen Statusänderungen für den Service durchführen. Sie werden bemerken, dass es insgesamt sieben Statuswechsel gibt (bei t3, t4, t5, t9, t12, t16 und t19). Ohne Gewichtung der Statuswechsel über die Zeit würde dies einen Gesamtwert von 35% ergeben:
(7 beobachtete Statuswechsel / 20 mögliche Statuswechsel) * 100 = 35 %
Nachdem die Flatter-Erkennungslogik neueren Statuswechseln mehr Gewicht gibt als älteren, wird der eigentliche Wert in diesem Beispiel geringfügig kleiner sein als 35%. Lassen Sie uns annehmen, dass der gewichtete Prozentwert 31% ist...
Der errechnete Prozentwert für den Service (31%) wird dann gegen die Flatter-Schwellwerte verglichen, um zu sehen, was passiert:
- wenn der Service bisher nicht flatterte und 31% gleich oder größer als der hohe Flatter-Schwellwert ist, nimmt Nagios an, dass der Service gerade angefangen hat zu flattern.
- wenn der Service bereits flatterte und 31% unter dem niedrigen Flatter-Schwellwert liegt, nimmt Nagios an, dass der Service gerade aufgehört hat zu flattern.
Wenn keine der beiden Bedingungen zutrifft, dann macht die Flatter-Erkennungslogik nichts weiteres mit dem Service, da er entweder (noch) nicht flattert oder bereits flattert.
die Flatter-Erkennung für Services
Nagios prüft jedes Mal, wenn der Service geprüft wird (egal ob aktiv oder passiv), ob ein Service flattert.
Die Flatter-Erkennungslogik für Services arbeitet wie in dem obigen Beispiel beschrieben.
die Flatter-Erkennung für Hosts
Host-Flatter-Erkennung arbeitet in einer ähnlichen Weise wie die Service-Flatter-Erkennung, mit einem wichtigen Unterschied: Nagios wird versuchen zu prüfen, ob ein Host flattert, wenn:
- der Host geprüft wird (aktiv oder passiv)
- manchmal, wenn ein Service geprüft wird, der mit dem Host verbunden ist. Genauer gesagt, wenn wenigstens x der Zeit vergangen ist, seit die letzte Flatter-Erkennung durchgeführt wurde, wobei x dem Durchschnittsintervall aller Services entspricht, die mit dem Host verbunden sind.
Warum wird das gemacht? Bei Services wissen wir, dass die minimale Zeit zwischen zwei aufeinander folgenden Flatter-Erkennungsroutinen gleich dem Service-Prüfintervall sein wird. Allerdings werden Sie Hosts wahrscheinlich nicht auf einer regelmäßigen Basis überwachen, so dass es kein Prüfintervall gibt, das in der Flatter-Erkennungslogik benutzt werden kann. Außerdem ist es sinnvoll, dass die Prüfung eines Service der Erkennung eines Host-Flatterns dienen sollte. Services sind Attribute eines Hosts bzw. bezogen auf Dinge, die mit dem Host verbunden sind. Auf jeden Fall ist es die beste Methode, die ich gefunden habe, um festzulegen, wie oft die Flatter-Erkennung auf einem Host ausgeführt werden kann.
Flatter-Erkennungsschwellwerte
Nagios benutzt verschiedene Variablen, um die Schwellwert-Prozentsätze der Statusänderungen festzulegen, die es für die Flatter-Erkennung nutzt. Für Hosts und Services gibt es hohe und niedrige globale und Host- und Service-spezifische Schwellwerte, die Sie konfigurieren können. Nagios wird die globalen Schwellwerte für die Flatter-Erkennung nutzen, wenn Sie keine Host- oder Service-spezifischen Schwellwerte angegeben haben.
Die Tabelle unten zeigt die globalen und die Host- oder Service-spezifischen Variablen, die die verschiedenen Schwellwerte kontrollieren, die bei der Flatter-Erkennung benutzt werden.
| Objekt-Typ | Globale Variable | Objekt-spezifische Variablen |
|---|---|---|
| Host |
low_host_flap_threshold high_host_flap_threshold |
low_flap_threshold high_flap_threshold |
| Service |
low_service_flap_threshold high_service_flap_threshold |
low_flap_threshold high_flap_threshold |
Zustände, die für die Flatter-Erkennung benutzt werden
Normalerweise wird Nagios die Ergebnisse der letzten 21 Prüfungen eines Hosts oder Service verfolgen, unabhängig vom Prüfergebnis (Host-/Service-Zustand), um sie für die Flatter-Erkennungslogik zu benutzen.
 Hinweis: Sie können durch die flap_detection_options-Direktive
in Ihren Host- oder Service-Definitonen verschiedene Host- oder Service-Zustände von der Nutzung in der Flatter-Erkennungslogik ausschließen.
Diese Direktive erlaubt Ihnen die Angabe, welche Host- oder Service-Zustände (z.B. "UP", "DOWN", "OK", "CRITICAL") Sie für die Flatter-Erkennung
benutzen wollen. Wenn Sie diese Direktive nicht nutzen wollen, werden alle Host- und Service-Zustände in der Flatter-Erkennung benutzt.
Hinweis: Sie können durch die flap_detection_options-Direktive
in Ihren Host- oder Service-Definitonen verschiedene Host- oder Service-Zustände von der Nutzung in der Flatter-Erkennungslogik ausschließen.
Diese Direktive erlaubt Ihnen die Angabe, welche Host- oder Service-Zustände (z.B. "UP", "DOWN", "OK", "CRITICAL") Sie für die Flatter-Erkennung
benutzen wollen. Wenn Sie diese Direktive nicht nutzen wollen, werden alle Host- und Service-Zustände in der Flatter-Erkennung benutzt.
die Flatter-Behandlung
Wenn bei einem Service- oder Host das erste Mal Flattern erkannt wird, wird Nagios:
- eine Meldung protokollieren, dass der Service oder Host flattert
- einen nicht-permanenten Kommentar zum Host oder Service hinzufügen, dass er flattert
- eine "flapping start"-Benachrichtigung für den Host oder Service an die betreffenden Kontakte versenden
- andere Benachrichtigungen für den Service oder Host unterdrücken (das ist einer der Filter in der Benachrichtigungslogik)
Wenn ein Service oder Host aufhört zu flattern, wird Nagios:
- eine Meldung protokollieren, dass der Service oder Host nicht mehr flattert
- den Kommentar löschen, der zum Service oder Host hinzugefügt wurde, als dieser anfing zu flattern
- eine "flapping stop"-Benachrichtigung für den Host oder Service an die betreffenden Kontakte versenden
- die Blockade von Benachrichtigungen für den Service oder Host entfernen (Benachrichtigungen sind nach wie vor an die normale Benachrichtigungslogik gebunden)
Aktivieren der Flatter-Erkennung
Um die Flatter-Erkennungsmöglichkeiten in Nagios zu aktivieren, müssen Sie folgendes tun:
- setzen Sie die enable_flap_detection-Direktive auf 1.
- setzen Sie die flap_detection_enabled-Direktive in Ihren Host- und Service-Definitionen auf 1.
Wenn Sie die Flatter-Erkennung auf einer globalen Ebene deaktivieren wollen, setzen Sie die enable_flap_detection-Direktive auf 0.
Wenn Sie die Flatter-Erkennung nur für einige Hosts oder Services deaktivieren wollen, nutzen Sie die flap_detection_enabled-Direktive in den Host- oder Service-Definitionen, um das zu tun.
 Siehe auch: Status-Typen
Siehe auch: Status-Typen